
Una delle funzionalità più interessanti del gestionale “Adempiere” è proprio la virtualizzazione di tutto il database all’interno dell’application dictionary.
Questo rende il sistema estremamente flessibile ed in grado a far fronte a qualsiasi modifica a livello di database in maniera semplice e veloce senza stravolgere tutta l’intera applicazione.
Per avere un’idea di ciò che intendo spiegare farò qualche esempio in modo da studiare tutte le funzionalità della finestra “Tabella“.
Maschera tabella
Aprendo, appunto, la maschera “Tabella” da ruolo utente “System Administrator” possiamo identificare una schermata simile a quella in figura.
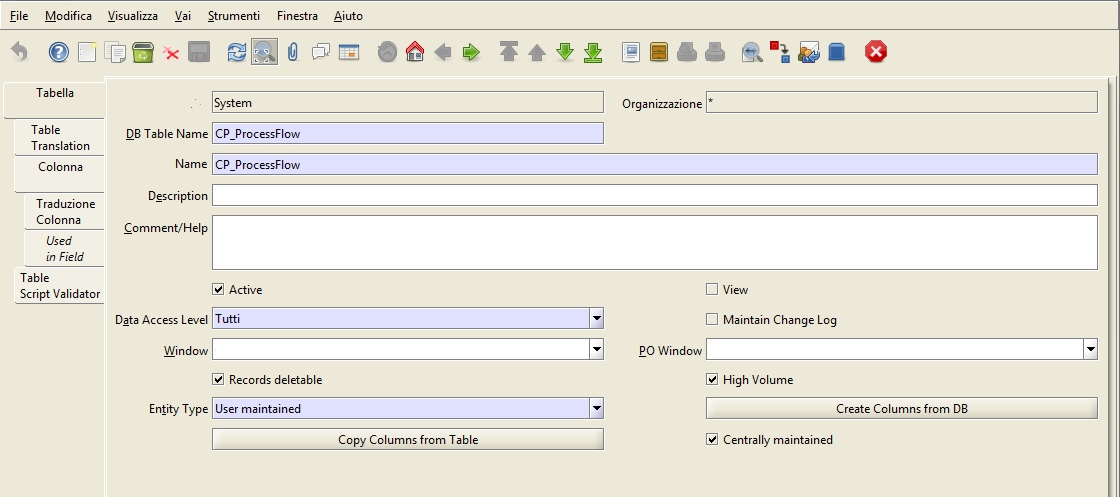
Nel nostro caso ho selezionato la tabella “CP_ProcessFlow” che corrisponde ad una tabella fisica precedentemente creata da me sul database. In realtà si possono selezionare tante altre tabelle native di Adempiere.
Ogni tabella ha quindi una sua virtualizzazione all’interno dell’application dictionary e specificatamente all’interno di “AD_TABLE“.
Guardiamo punto per punto tutte le funzionalità della maschera “Tabella“:
Se proviamo ad osservare la figura notiamo che i primi campi “Client, Organizzazione, Name, Description, Comment/Help, Active” sono tutti campi presenti in tutte le tabelle di Adempiere: client ed organizzazione rappresentano l’azienda e l’organizzazione aziendale con cui si è eseguito l’accesso.
I campi Name, Descriprion, Comment/Help, Active rapppresentano rispettivamente il nome della tabella, la descrizione funzionale, alcuni commenti o suggerimenti sulla tabella e se la tabella è attiva o meno.
Il campo DB table name è molto importante in quanto identifica il nome della tabella registrata sul database fisico.
Successivamente troviamo il campo Data Access Level. In questo campo possiamo definire il livello di accesso ai dati della tabella; se, ad esempio, voglio che tutti gli utenti vedano i dati allora inserisco (come nel nostro esempio) il valore tutti. Posso decidere di far visualizzare i dati soltanto agli utenti della mia organizzazione (in questo caso inserisco organizzazione) oppure soltanto agli utenti della mia azienda (in questo caso inserisco azienda).
Al fianco di data access level troviamo il flag Mantain Change Log. Questo valore indica se vogliamo che tutte le modifiche fatte su questa tabella debbano essere registrate nel sistema di logging. In questo modo gli amministratori hanno la possibilità di sapere se chi e quando ha eseguito una modifica sulla tabella presa in considerazione.
I campi Window e POWindow identificano le finestre associate a tale tabella. Non è obbligatorio che siano compilati ma sono molto utili per quelle tabelle che svolgono un doppio ruolo funzionale. Ad esempio sulla tabella C_Order possono essere associate due finestre: una per gli ordini di acquisto e l’altra per gli ordini di vendita. In questo caso inserirò su POWindow la finestra relativa agli ordini di acquisto (purchase order), su window la finestra relativa agli ordini di vendita (sales order).
Questo può essere utile quando da una determinata maschera (ad esempio dalla fattura di vendita) voglio accedere ai relativi ordini di vendita facendo click e zoom sul campo “ordini”. Il sistema mi proporrà la finestra settata nel campo window che in questo caso saranno gli ordini di vendita.
Il flag record deleteable indica che è possibile eliminare le righe all’interno della tabella.Il flag High Volume indica che la tabella può presentare un’elevata quantità di righe. Se viene selezionata allora ogni volta che accedo ad una finestra di questa tabella il sistema mi propone una maschera iniziale di filtro dei dati.
Il tasto create columns from DB è un processo molto utile che, in base al nome inserito su db table name, acquisisce le informazioni delle colonne del database e le registra all’interno dell’application dictionary (in AD_Column) copiandone anche gli attributi principali. Ad esempio, importa le chiavi primarie, il tipo di dati, la lunghezza dei campi ecc..
Il tasto Copy Column from Table non fa altro che copiare le colonne da un’ altra tabella presente nell’application dictionary.
Maschera colonna
Una volta copiati i dati delle colonne possiamo accedere al tab “colonna” come in figura.
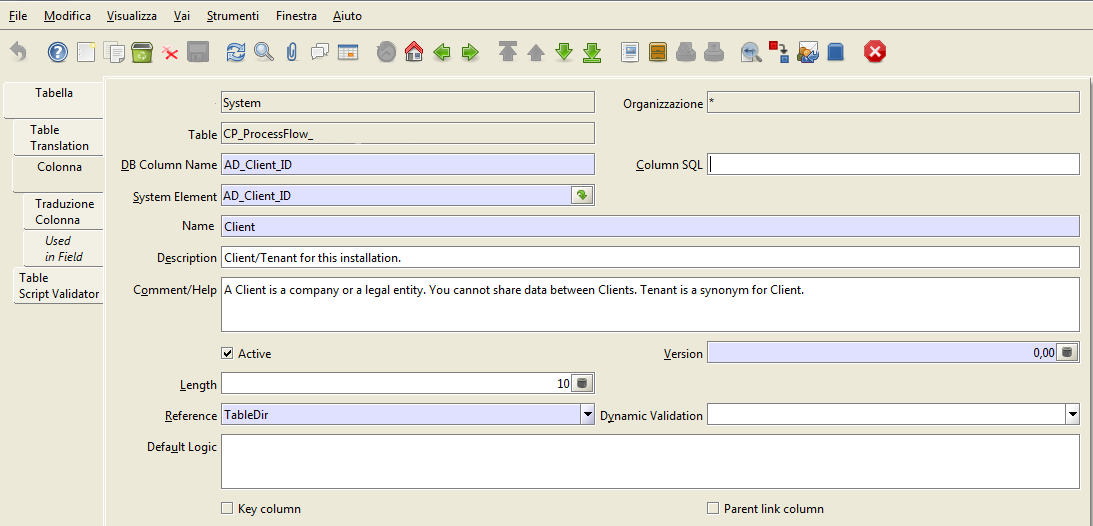
In questa maschera abbiamo altrettanti campi molto interessanti dal punto di vista della flessibilità.
Anzitutto ritroviamo gli stessi campi Name, Description, Active, Organizzazione, Client presenti in tutte le maschere.
Il campo DB Column Name identifica lo stesso nome della colonna così come viene scritto sul database.
Il campo column SQL rappresenta uno strumento molto utile per assegnare dei valori alla colonna sulla base di un codice SQL. Tutto ciò è fatto soltanto a livello dell’application dictionary.
E’ possibile inserire ad esempio codice come (SELECT Value FROM M_Product p WHERE p.M_Product_ID=M_MovementLine.M_Product_ID) in cui viene inserito nella colonna il valore “value” preso dalla tabella M_Product con determinate condizioni inserite in where.
Oppure è possibile inserire codice un pò più complesso come (SELECT MAX(p.PayAmt)-COALESCE(SUM(a.Amount),0) FROM C_Payment p LEFT OUTER JOIN C_PaymentAllocate a ON (p.C_Payment_ID=a.C_Payment_ID) WHERE p.C_Payment_ID=C_PaymentAllocate.C_Payment_ID) dove il valore della colonna è il risultato della differenza di alcune funzioni aggregate.
Ad ogni modo è possibile attribuire il valore di una colonna come risultato di una query SQL.
Il campo length identifica la lunghezza del campo del database. Ad esempio per una stringa lunga 10 caratteri viene registrato il valore 10. Anche questo campo può essere modificato a piacere soltanto a livello di Application Dictionary. Se ad esempio si vuole modificare la lunghezza di una stringa è sufficiente modificare questo valore senza eseguire un alter table sul DB. Esiste poi un processo su questa maschera che permette la sincronizzazione della colonna sul database facendo eseguire dal sistema l’operazione alter table.
Il campo “Reference” è molto importante e rappresenta la tipologia di dato della colonna. In automatico il sistema riconosce se la colonna contiene caratteri, date, numeri ecc…ed imposta un valore di riferimento più consono per quel dato. Se, ad esempio, la colonna è una data allora il sistema imposta il valore “data”; l’attributo viene poi associato a tutte le maschere di questa colonna proponendo un calendario all’inserimento di dati.
Se invece la colonna è di tipo numerico allora imposta l’attributo number mostrando una calcolatrice ogni volta che si vogliono inserire dati su questa colonna.
Ci sono diversi tipi di riferimenti sul gestionale ma se ne possono creare degli altri a seconda delle necessità.
Uno dei riferimenti più utilizzati è tableDir. Questo riferimento permette la navigazione da una tabella all’altra con la funzionalità di zoom. Il tableDir si assegna alle colonne che rappresentano le foreign key ovvero chiavi primarie di altre tabelle. Ad esempio all’interno della tabella C_Order esiste la colonna C_BPartner_ID che sarà una chave esterna verso la tabella C_BPartner. Questa colonna sarà marcata con Reference TableDir e ciò permette la navigazione alla finestra dei business partner una volta che si esegue zoom sul campo C_Bpartner_ID dalla maschera degli ordini.
Se viene selezionato il valore di riferimento come data time allora apparirà un altro campo dove poter inserire il format pattern della data. Ad esempio se si vuole visualizzare la data con formato giorno/mese/anno e l’ora ora:minuti:secondi basta inserire in formati pattern il seguente valore: dd/MM/yy hh:MM:ss
Il valore selection column identifica le colonne che verranno utilizzate per creare il filtro di ricerca nella maschera della tabella.
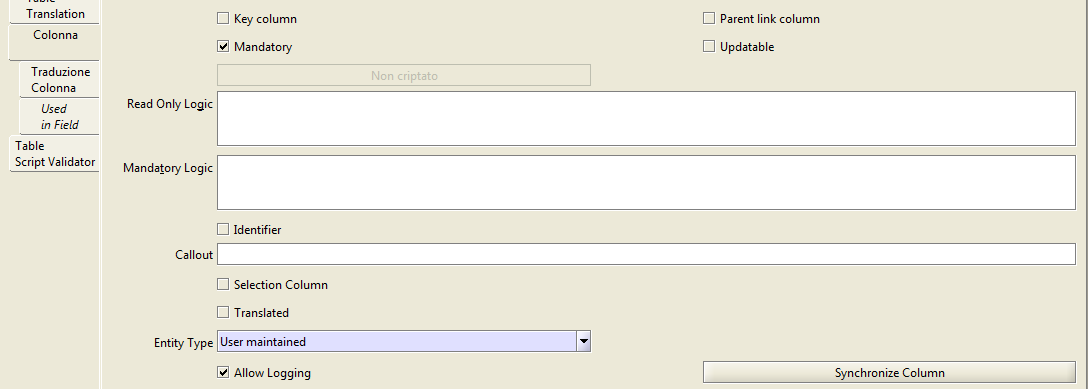
Le colonne default logic, mandatory logic, read only logic rappresentano rispettivamente il valore di default, il valore per cui il campo è obbligatorio, il valore per cui il campo deve essere soltanto in modalità lettura e non in scrittura.
Un esempio di valori che possono essere inseriti sono: @campo_colonna@ dove le due chioccioline identificano il valore del campo colonna. Oppure @#variabile_contesto@ dove l’elemento # identifica una variabile di contesto.
Questo vuol dire che io posso registrare come valore di default il nome utente all’accesso del sistema. Per fare ciò basta inserire in default logic sulla colonna che chiamo Utente la dicitura: @#AD_User@. Se nella tabella ho già un valore impostato di AD_USER_ID allora posso creare questo script per recuperare il nome dell’utente ed inserirlo in default: @SQL=select AD_User_Name From AD_User u where u.AD_User_ID=@AD_User_ID@@
Il campo callout è un altro campo che rende ancora più flessibile il valore di una colonna. E’ possibile creare una classe java indipendente ed assegnarla a questa colonna in modo da creare una reazione al semplice inserimento di un valore.
Ad esempio, posso inserire il valore del fornitore dentro la maschera “ordine di acquisto” e, nello stesso momento, far compilare tutti i campi della maschera associati a questo fornitore; quindi, inserito il fornitore posso prevedere di far compilare anche l’indirizzo, il contatto, il codice fiscale ecc…
Il flag parent link column serve per creare una gerarchia all’interno delle tabelle. Ad esempio, la maschera degli ordini di acquisto è composta da due tabelle: la prima è C_Order che rappresenta la testata del documento e la seconda è C_OrderLine che rappresenta le righe dell’ordine; quest’ultima tabella avrà una colonna che si chiama C_Order_ID in modo da identificare l’ID di C_Order di riferimento. Per far in modo che la tabella C_OrderLine sia gerarchicamente una figlia di C_Order allora si imposta il valore parent link column a true sulla sua chiave esterna C_Order_ID.
Questo valore fa in modo che sulla maschera degli ordini, quando voglio visualizzare le righe di un ordine, verranno filtrate soltanto le righe corrispondenti all’ordine C_Order_ID selezionato.