
L’algoritmo Adaline (ADaptive LInear NEuron) è un algoritmo di convergenza dell’apprendimento. Ciò vuol dire che i pesi non si aggiornano ad ogni epoch sulla base di una funzione di attivazione binaria (come nel caso del Perceptron), ma si aggiornano sulla base di una funzione di attivazione lineare.
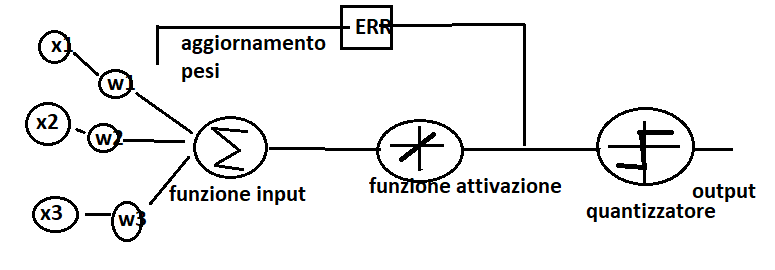
Come vediamo nel grafico sopra, la differenza con l’algoritmo Perceptron è che i pesi si aggiornano attraverso una funzione lineare ad ogni epoch. Questo consente di minimizzare la funzione di costo.
La funzione di costo è la funzione J che apprende i pesi in termini di somma dei quadrati degli errori (Sum Squared Errors – SSE) fra il risultato calcolato e la vera etichetta della classe.
J(w) = 1/2 Σi (y(i) – Φ (z(i)))2
Quali sono i vantaggi di questa funzione? Questa funzione di costo è differenziabile ed è convessa. Questo ci consente di utilizzare un algoritmo di discesa del gradiente per trovare i pesi che minimizzano la funzione di costo.
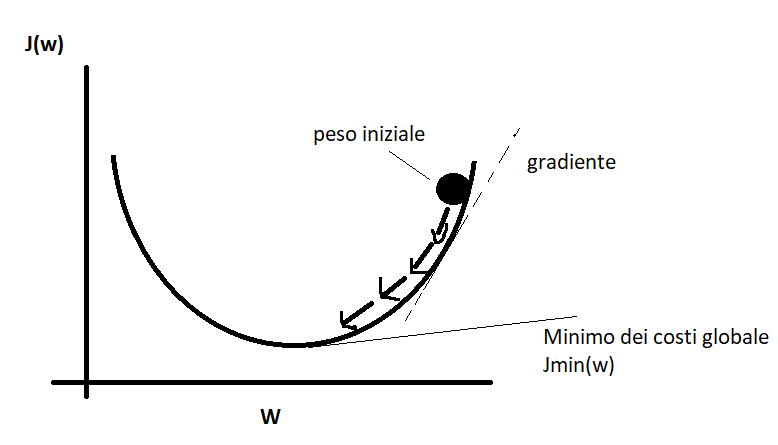
Come si può vedere nel grafico sopra, i pesi si aggiornano in base alla funzione di costo descritto in precedenza. A partire quindi da un peso iniziale (w), i pesi si aggiorneranno fino a raggiungere il minimo dei costi globale ed allontanandoci quindi dal gradJ(w)
Il cambiamento del peso è definito in questo modo:
Δ(w)= -η gradJ(w)
Per calcolare il gradiente è necessario fare la derivata parziale della funzione J ad ogni peso wi. Il vantaggio dell’algoritmo è che i pesi vengono aggiornati simultaneamente a differenza del Perceptron che venivano aggiornati ad ogni iterazione.